Anomaly Detection
『异常检测』是无监督学习中的又一类算法,其目的是根据训练集中一堆无标记的数据,判断出要测试的数据是否异常。Andrew Ng给出的三个应用例子是plane engine、fraud detection和monitoring computers in a data center.结合下图说明一下什么是『异常检测』。
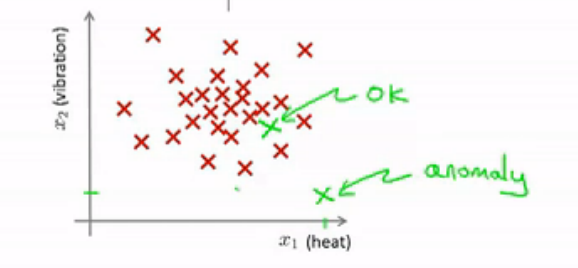
图中红色标记的是训练集中的飞机引擎,横纵坐标是飞机引擎的两个特征(feature)。对于一个新的飞机引擎(绿色标志),观测其特征,若落在上面那个位置,我们很容易判断这个引擎是正常的,若落在下面的位置,则有足够的理由将其标记为异常。
『异常检测』的原理:这一类的数据一般呈正态分布(又叫高斯分布),根据数据的特征向量,容易得出其概率大小,然后跟某个事前约定好的数值进行比较,如果概率比这个值还小,我们就判断这个数据检测出了异常。
###高斯分布
通过下图回顾一下高斯分布的概念。
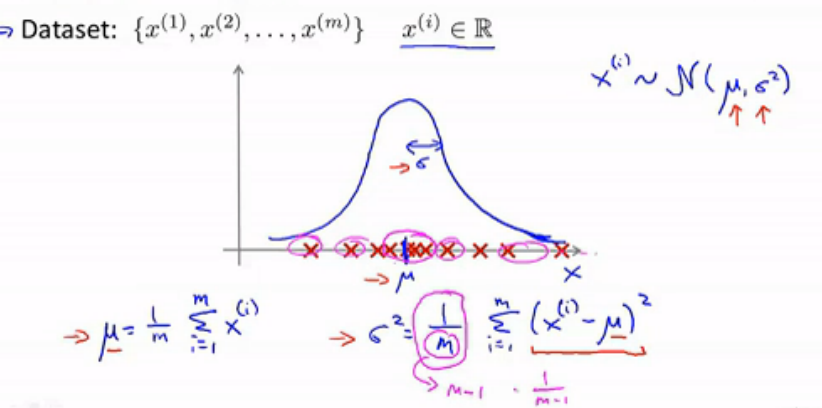
从上图可以看出,根据红色标记的数据的分布情况,我们可以大致画出其分布曲线,形态类似正态分布,那么我们不妨就假设数据是服从正态分布的。现在的任务是,根据训练集中的数据,估计参数 μ、σ2。上图底部给出了参数估计的两个公式。
参数 μ、σ2估计出来之后,根据正态分布的公式,便得到了数据分布式。对于新给的测试数据,输入其特征向量,便得到概率的大小了。
###算法
训练集中有m个数据,特征向量为n维。假设每个特征Xi都服从正态分布。那么该特征向量出现的概率为P(x)=P(x1;μ1,σ21)*P(x2;μ2,σ22)...P(xi;μi,σ2i)...P(xm;μm,σ2m)。 在这里,我们假设“各特征之间是相互独立的”。
总结一下,「anomaly detection」的算法大概三个步骤:
- 选择进行『异常检测』要使用的特征,下面会介绍。
- 计算每个特征的μ、σ2。
- 对于新的数据,求出P(x),与约定好的数据进行比较,若是大于,则OK,否则异常。
###选择特征
不是所有的特征都能够用来进行异常检测,我们要使用的特征应该明显服从正态分布的特征,异常数据的数量要远低于正常数据。有时需要create new features,例如,x1可能不服从正态分布,但log(x)服从正态分布,那么我们使用log(x)作为要使用的特征。
###异常检测和有监督学习的区别
异常检测,实际上也是一种有标记的学习,标记就是数据是否异常。那么是否可以直接使用有监督学习中的算法呢?不能!两者有些区别:
- 异常检测中,(y=1)的数据远少于(y=0)的数据。而有监督学习中,两者数量都很大。
- 异常检测中,异常的种类很多,而数量很少,无法通过学习获得model。而有监督学习中,异常的种类少数量多,足够用来学得一个有效的model。
###多元正态分布
在上面的异常检测算法中,我们假设各特征值相互独立,并拆开来分别计算μ和σ。在大多数情况下这么做是完全可以的,也有少数情况会出现问题,如下图。
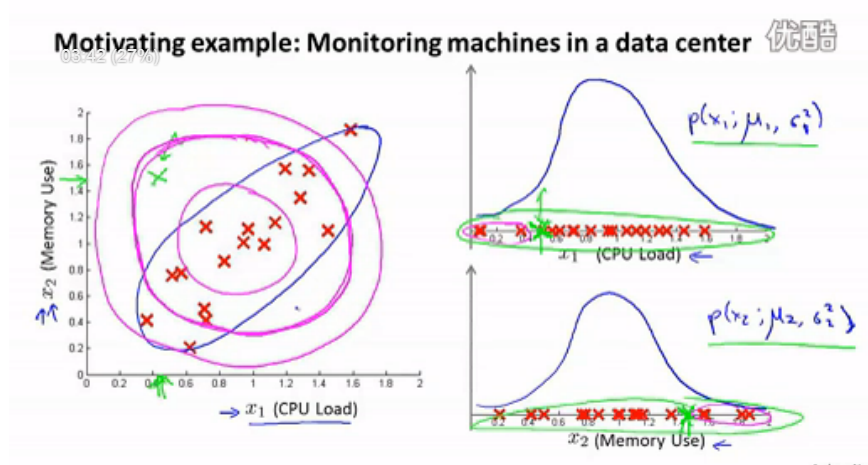
图中绿色标记的数据,单独按照特征x1和x2来计算,都是正常数据。但事实上,这是一个异常的数据。这种情况下,我们需要使用多元正态分布来做异常检测。
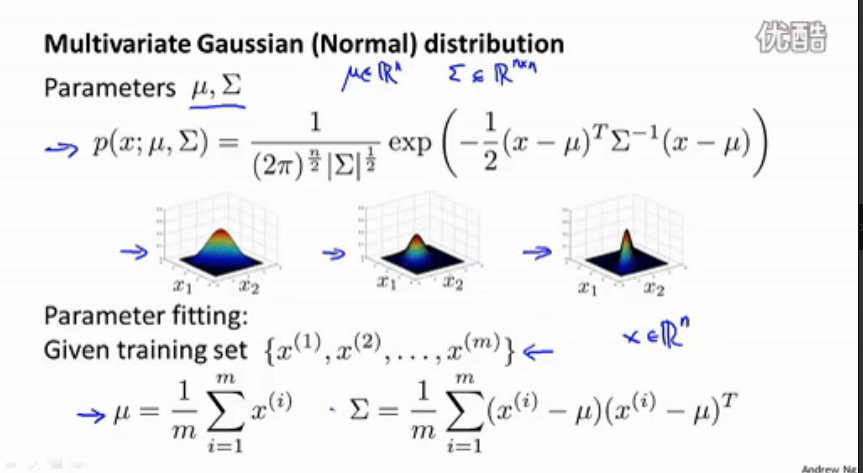
多元正态分布的公式上图已给出,图中底部时是参数估计的公式。使用多元正态分布进行异常检测,方法和使用正态分布时(original model)类似,不做介绍了。
需要指出的是,original model是多元正态分布的一个特例。此时,Σ是一个对角阵,对角线上的数据是σ1…σn的平方。
###when to use which
- original model 有时需要 manually create features,而多元正态分布中直接使用全部特征。
- 前者 computationally cheaper。
- 前者 m 可以很小,而后者中,m>n,否则Σ有可能不存在逆矩阵。
- 前者更常用一些。